



NVIDIA GeForce GTX 580显卡评测
不同以往的纹理单元设计
在GF110/100中,每个SM配备了四个纹理单元,共计64个纹理单元。和上一代GT200以及竞争对手Cypress动辄80个纹理单元相比,GF110/100的纹理单元数量不但没有提升,反而下降。这是为什么呢?
事实上,在GT200架构中,多三个SM共享一个纹理引擎,该纹理引擎包括八个纹理定址单元和过滤单元。而G92则是两个SM共享一个纹理引擎。但NVIDIA认为单纯地添加纹理单元的数量并不能有效提升GPU的纹理贴图能力,甚至造成部分单元闲置浪费。因此在GF100中,NVIDIA通过将纹理单元移植到SM中的设计来提升纹理单元的使用效率和时钟频率——每个SM都配备了四个专属的纹理单元和一个12KB的纹理高速缓存。一个纹理单元在一个时钟周期内能够计算一个纹理地址并获取四个纹理采样,可以支持包括双线性、三线性在内的各向异性过滤模式。需要特别注意的是,GF110/100打破了之前将纹理单元设计在SM阵列之外的做法,将纹理单元整合在SM阵列里面,在一定程度上提升了纹理单元的效率。
创新的Shared Memory和L1/L2缓存
在GF110/100中,每个SM阵列里面拥有一个容量很小的内存空间,即Shared Memory,可以用于数据交换,程序员可以方便自由使用。有了Shared Memory后,同一个Thread block内的线程可以共享数据,极大地提升了NVIDIA GPU在进行GPU Computing应用时的效率。
虽然Shared Memory对许多计算都有帮助,但它并不适用于所有的问题。佳化的内存层次架构方案就是同时提供Shared Memory和Cache,GF110/100就采用了这样的设计。在G80和GT200中,每个SM都有16KB的Shared Memory。而在GF110/100中,每个SM拥有64KB的Shared Memory,能配置为48KB Shared Memory+16KB L1 Cache或者16KB Shared Memory+48KB L1 Cache的模式(G80和GT200不具备L1/L2 Cache)。程序员可以自己编写一段小的程序,把Shared Memory当成Cache来使用,由软件负责实现数据的读写和一致性管理。而对那些不具备上述程序的应用程序来说,也可以直接自动从L1 Cache中受益,显著缩减运行CUDA程序的时间。过去,GPU的寄存器如果发生溢出的话,会大幅度地增加存取时延。有了L1 Cache以后,即使临时寄存器使用量增加,程序的性能表现也不至于大起大落。
另外,GF110/100还提供了768KB的一体化L2 Cache,L2 Cache为所有的Load/Store以及纹理请求提供高速缓存。对所有的SM阵列来说,L2 Cache上的数据都是连贯一致的,从L2 Cache上读取到的数据就是新的数据。有了L2 Cache后,就能实现 GPU高效横跨数据共享。对于那些无法预知数据地址的算法,例如物理解算器、光线追踪以及稀疏矩阵乘法都可以从GF110/100的内存层次设计中显著获益。而对于需要多个SM读取相同数据的滤镜以及卷积核(convolution kernel)等算法同样能因为这个设计而获益。
改进的ROP单元
在GF110/100上,NVIDIA对ROP单元进行了全新设计,大幅提升了数据吞吐量与效率。GF110/100包含六个ROP分区,一个ROP分区包括了八个ROP单元,共计48个ROP单元(GT200具备八个ROP分区,并与八个64bit的显存控制器绑定,一个ROP分区包含四个ROP单元。)。一个ROP单元能够在一个时钟周期内输出一个32bit整数像素。理论上,由于ROP的压缩效率和ROP单元数量的提升,GF110在8x抗锯齿下的性能会得到明显改善。
此外,得益于更多的原子操作单元以及L2缓存,GF110的原子内存操作性能相对以往的架构来说得到了巨大的提升。对同一地址的原子内存操作,GF110的运算速度是GT200的20倍,而对相邻内存区域的操作则达到7.5倍。
完整的曲面细分单元设计
我们知道,曲面细分作为DirecX 11中的重要技术,可以显著提升我们的游戏体验。但曲面细分会将特定帧中的三角形密度增加数十倍,给光栅化等串行化运算单元带来很大的压力,因此对图形流水线的优化就迫在眉睫。而GeForce GTX 480所采用的GF100图形架构就是专为DirectX 11而设计,具备15个PolyMorph Engine(多形体引擎,又称之为曲面细分单元)和四个Raster Engine(光栅化引擎),因此在引入曲面细分设计的DirectX 11游戏中将会获得更大的优势(曲面细分设计越复杂,其优势会越明显)。而GeForce GTX 580采用的GF110核心,则具备完整的16个PolyMorph Engine,在DirectX 11游戏的应用中会更加优秀。
具体来说,在每个SM阵列里面具备可扩展的PolyMorph Engine,共计16个,可以实现较高的三角形速率,每个PolyMorph Engine均拥有专属的顶点获取单元以及Tessellator,极大地提升了几何性能。与之呼应的则是分别常驻于四个GPC里面的四个并行的Raster Engine,它们能够在每个时钟周期内设置多四个三角形,并且在三角形Fetch、Tessellation以及光栅化操作方面具备很强的性能。
这种专为DirectX 11而设计的图形架构与AMD新的Barts图形架构有很大的区别。Barts是在Cypress基础上演变而来,仍然只具备1个曲面细分单元Tessllator Gen7。而Barts相对于Cypress,曲面细分性能有所提升的原因并不是因为增加了曲面细分单元的数量,而是来源于线程分配模块的增强。不过这只能治标,却无法治本。因此在高负荷曲面细分计算环境下,Barts的曲面细分性能会大幅下降,此时即使拥有增强的线程分配模块设计也起不了太大的作用,因为主要的瓶颈在曲面细分单元的数量和效率上。
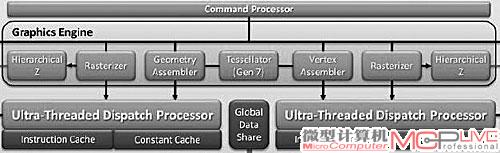
Barts仍然只有一个曲面细分单元,但增加了Ultra-Threaded Dispatch Processor的数量,一定程度提升了曲面细分的性能。
当然,由于曲面细分很耗费GPU资源,现在游戏厂商在使用这项技术时相对比较谨慎。初的一些DirectX 11游戏基本没有或者加入了很少的曲面细分技术,因为当时的显卡的曲面细分性能并不算强。而现在随着显卡曲面细分性能的增强,一些DirectX 11游戏会加入更多的曲面细分技术,GF110的曲面细分优势会进一步体现出来。

